手把手教你用Python获取最全NBA数据
喜欢NBA的朋友可能知道有个非常全面和专业的NBA中文数据库--Stat-NBA

上面不仅有所有球队球员的各项数据,还统计了从NBA创立的的1946年来的所有数据,还是中文版本的,还可以通过各种筛选进阶数据。但如果想要下载来自己分析,就比较麻烦。今天就专门写一个python如何获取stat-nba数据的教程,并用工具做一个简单的动态变化图。视频效果:
01 选取数据说到NBA数据,很多人首先想到的是得分榜,那今天我们就拿历年来的得分榜前10数据。
http://www.stat-nba.com/season/1946.HTML

这个页面可以获取到每个赛季的各项排行榜,而且重点是URL非常友好,使用的后缀是年份,这样我们只需要遍历所有年份的URL即可。
02 基本思路1.将要获取的目标网页的html源码保存起来;2.再使用etree进行提取页面element,etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法;3.将获取到数据按照要求格式保存到dataframe中;4.最后使用花火在线生成动态图工具使用的第三方包括:requests,lxml中的etree,pandas
03 流程与代码# 再使用etree进行提取页面element,etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符html = etree.HTML(html)print(type(html))print(html) # 使用html.xpath()提取指定标签的文本内容,xpath标签获取方式,可以在谷歌浏览器中,比如在上图的”乔福尔克斯“上面右键,# 选择copy-》copy xpath,即可得到://*[@id="allpts0"]/div[1]/div[1]/aplayer = html.xpath('//*[@id="allpts0"]/div[1]/div[1]/a')[0].textprint(player)
# 使用html.xpath()提取指定标签的文本内容,xpath标签获取方式,可以在谷歌浏览器中,比如在上图的”乔福尔克斯“上面右键,# 选择copy-》copy xpath,即可得到://*[@id="allpts0"]/div[1]/div[1]/aplayer = html.xpath('//*[@id="allpts0"]/div[1]/div[1]/a')[0].textprint(player)

获取到页面源码的element格式后,可以使用xpath轻松提前指定标签下的内容。从图中可以看出,得分榜的内容存放在一个div中,id=“allpts0"中,球员名称和数据存放在下面的div class='content'中,总共10个,那我们只需要把这10个标签下面的a和p标签内容获取到即可:
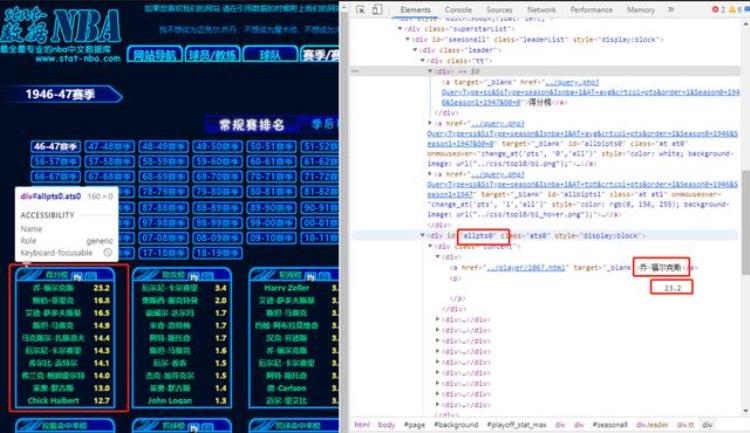 # 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}# 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}
# 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}# 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}
接下来,可以批量获取全部年份的得分榜数据
df = pd.DataFrame()for i in range(1946,2020): url = 'http://www.stat-nba.com/season/{}.html' url = url.format(str(i)) r = requests.get(url,verify=False) html = r.content.decode('utf-8') html = etree.HTML(html) rank = {} for j in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(j)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(j)))[0].text.strip()) # 转化成数值 rank[player] = data print(rank) df = df.append(pd.DataFrame(index=[i],data=rank))最终的数据是:
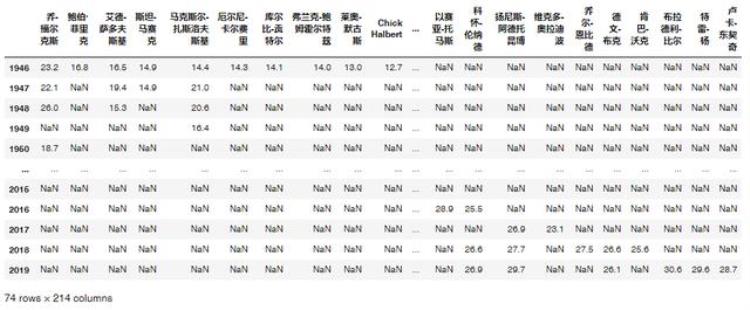
为了按照工具的数据格式要求,只需要稍微转置一下:
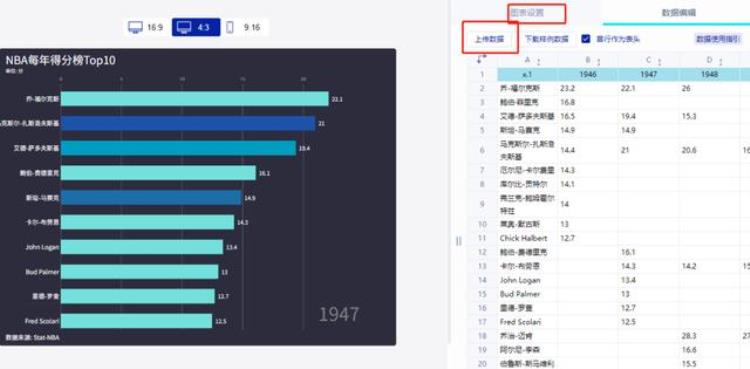
df.T.to_excel('ptsrank.xlsx','utf-8-sig')04 上传数据制作视频火花的URL:https://hanabi.data-viz.cn/templates
选择动态条形图即可。注:火花很多图表是付费的,免费的可以使用Flourish。
声明
1.本数据分析只做学习研究之用途,勿用他途,提供的结论仅供参考;
2.公开数据不建议抓取太多,以免对服务器造成负担,如有侵权,马上删除
本站声明:以上部分图文视频来自网络,如涉及侵权请联系删除
-
得马琳者得天下”神话还是“得樊振东者得天下”
马琳,樊振东 2025-05-25
-
陈梦的时代真的来了吗?刘国梁内心欣慰
陈梦,孙颖莎,刘国梁 2025-05-25
-
2022c罗世界杯附加赛几个进球c罗帮助球队力挽狂澜的比赛
世界杯 2025-05-11
-
樊振东张本智和乒乓球比赛
樊振东,张本智 2025-05-11
-
樊振东马龙乒乓球决赛
樊振东,马龙 2025-05-11
-
2008北京奥运会邮票现在值多少
奥运会 2025-05-11
-
樊振东夺冠后刘国梁的评价
樊振东,刘国梁 2025-05-11
-
刘国梁为什么一心扶持刘诗雯
刘国梁,刘诗雯 2025-05-11
-
活宝一枚!奥莫特训练结束一展歌喉 同时和小曾开玩笑
篮球,CBA,中国篮球,北京 2025-04-26
-
比卢普斯:很高兴看到活塞本赛季的崛起 他们很久没打季后赛了
篮球,NBA,活塞,开拓者 2025-04-26
